Интернет, пожалуй, самый большой источник информации (и дезинформации) на планете. Самостоятельно обработать множество ресурсов крайне сложно и затратно по времени, но есть способы автоматизации этого процесса. Речь идут о процессе скрейпинга страницы и последующего анализа данных. При помощи этих инструментов можно автоматизировать сбор огромного количества данных. А сообщество Python создало несколько мощных инструментов для этого. Интересно? Тогда погнали!
И да. Хотя многие сайты ничего против парсеров не имеют, но есть и те, кто не одобряет сбор данных с их сайта подобным образом. Стоит это учитывать, особенно если вы планируете какой-то крупный проект на базе собираемых данных.
С сегодня я предлагаю попробовать себя в этой интересной сфере при помощи классного инструмента под названием Beautiful Soup (Красивый суп?). Название начинает иметь смысл если вы хоть раз видели HTML кашу загруженной странички.
В этом примере мы попробуем стянуть данные сначала из специального сайта для обучения парсингу. А в следующий раз я покажу как я собираю некоторые блоки данных с сайта Minecraft Wiki, где структура сайта куда менее дружелюбная.
Этот гайд я написал под вдохновением и впечатлением от подобного на сайте realpython.com, так что многие моменты и примеры совпадают, но содержимое и определённые части были изменены или написаны иначе, т.к. это не перевод. Оригинал: Beautiful Soup: Build a Web Scraper With Python.
Цель: Fake Python Job Site
Этот сайт прост и понятен. Там есть список данных, которые нам и нужно будет вытащить из загруженной странички.

Понятное дело, что обработать так можно любой сайт. Буквально все из тех, которые вы можете открыть в своём браузере. Но для разных сайтов нужен будет свой скрипт, сложность которого будет напрямую зависеть от сложности самого сайта.
Главным инструментом в браузере для вас станет Инспектор страниц. В браузерах на базе хромиума его можно запустить вот так:
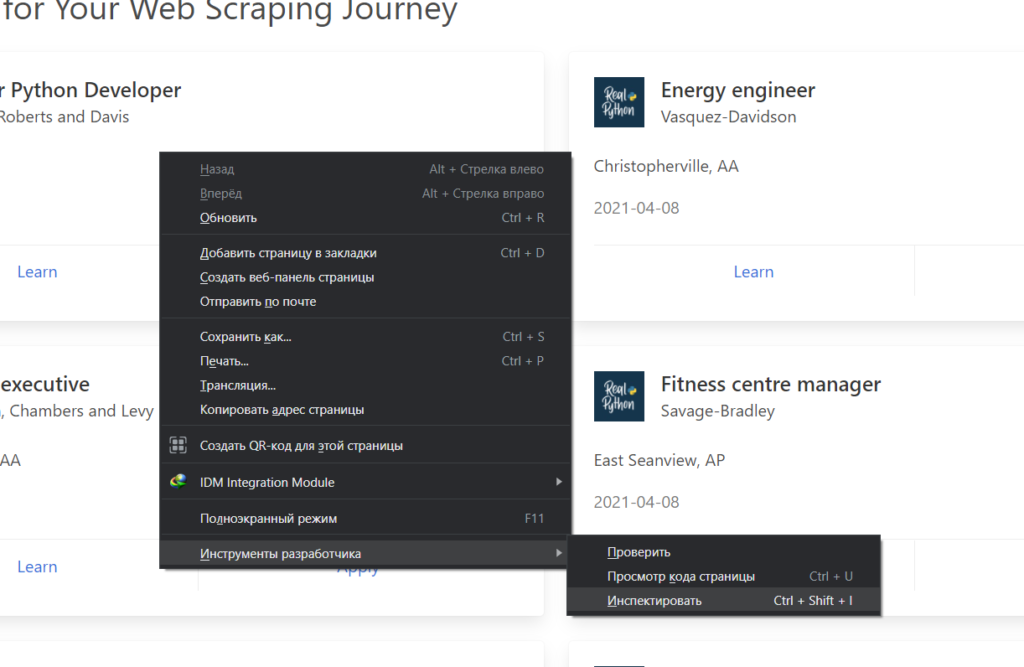
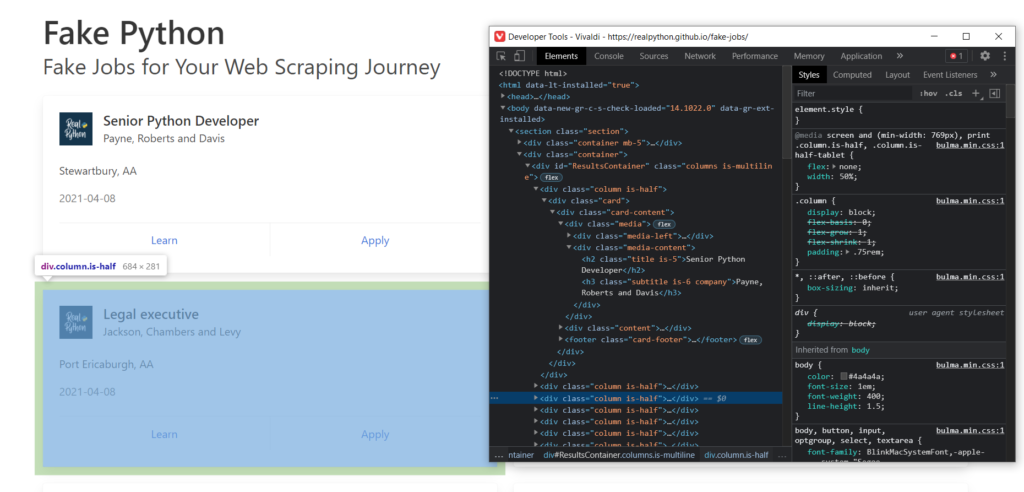
Он отображает полный код загруженной странички. Из него же мы будем извлекать интересующие нас данные. Если вы выделите блоки html кода, то при помощи подсветки легко сможете понять, что за что отвечает.
Ладно, на сайт посмотрели. Теперь перейдём в редактор.
Пишем код парсера для Fake Python
Для работы нам нужно будет несколько библиотек: requests и beautifulsoup4. Их устанавливаем через терминал при помощи команд:
|
1 |
python -m pip install beautifulsoup4 |
и
|
1 |
python -m pip install requests |
После чего пишем следующий код:
|
1 2 3 4 5 6 7 |
import requests from bs4 import BeautifulSoup URL = "https://realpython.github.io/fake-jobs/" page = requests.get(URL) soup = BeautifulSoup(page.content, "html.parser") |
Тут мы импортируем новые библиотеки. URL это строка, она содержит ссылку на сайт. При помощи requests.get мы совершаем запрос к веб страничке. Сама функция возвращает ответ от сервера (200, 404 и т.д.), а page.content предоставляет нам полный код загруженной страницы. Тот же код, который мы видели в инспекторе.
Для большего понимания можно вывести принтом оба варианта:
|
1 2 3 |
print(page) print(page.content) |

Первый дал ответ 200, т.е. ОК. А дальше идёт тот самый будущий суп из html, который нам и нужно будет разобрать.
В следующей строке и вступает в игру BeautifulSoup, куда мы передаём первым аргументом весь код страницы, а вторым указываем, что это анализировать будем именно html.
Хотите увидеть результат? Давайте выведем объект soup.
|
1 |
print(soup) |
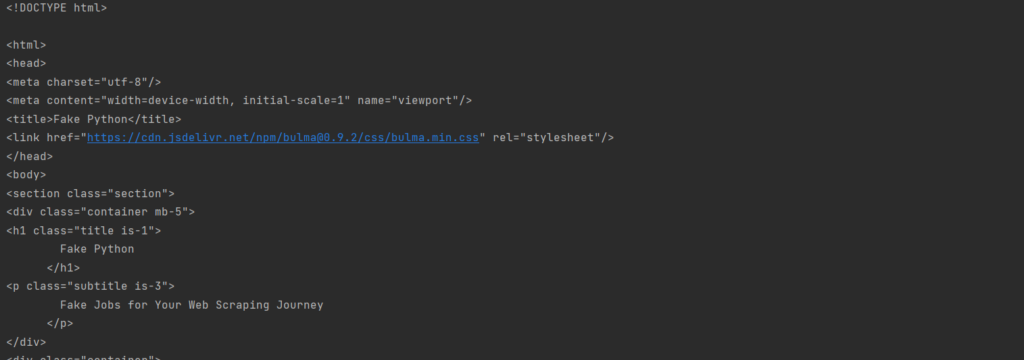
Да, это всё тот же код, но уже сейчас куда более читаемый. Технически, вы уже получили код страницы при помощи python, но информация в таком виде содержит слишком много лишнего. И сейчас мы научимся его отсекать.
Ищем элементы по ID
Как вы могли заметить, наблюдая за html кодом, есть много блоков с различными параметрами, class, id и т.д. Часто именно id делает элементы разметки уникальными и по этому параметру можно найти интересующие нас части.
Если брать во внимание разбираемый нами сайт, то вы могли заметить, что все отдельные карточки находятся внутри одного объекта div с id = ResultsContainer:
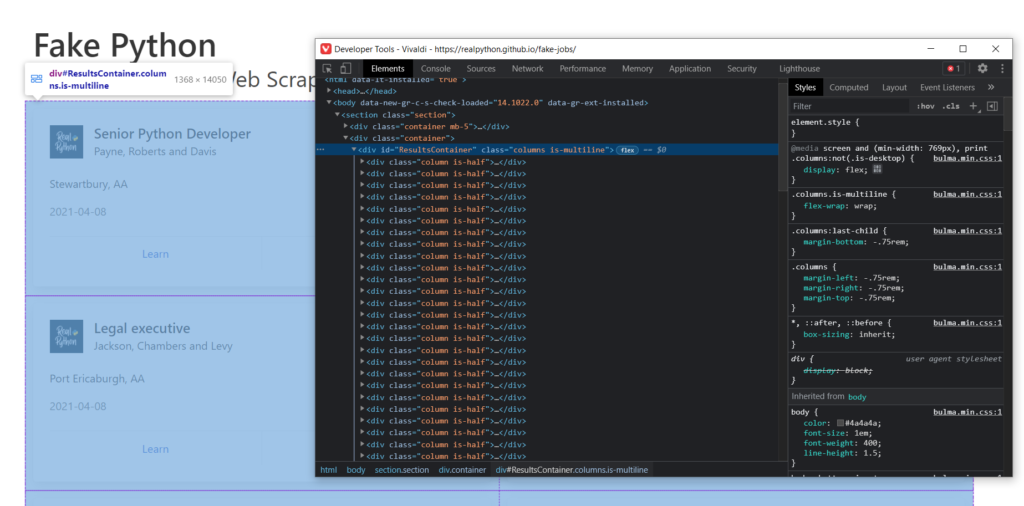
Это нам подходит. Так и пишем, а заодно и выведем результат:
|
1 2 3 |
results = soup.find(id="ResultsContainer") print(results) |
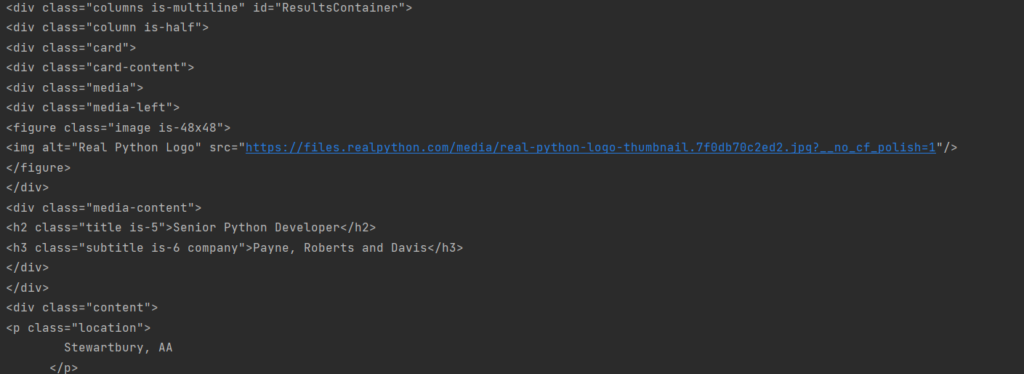
Теперь мы получили только выбранный блок. Да, всё ещё не особо читаемое, да и форматирование не отражает иерархии. С первым мы разберемся далее, а вот второе исправить достаточно просто. Вместо простого принта объекта мы можем использовать функцию prettify.
|
1 |
print(results.prettify()) |
А результат станет несколько приятнее для чтения:
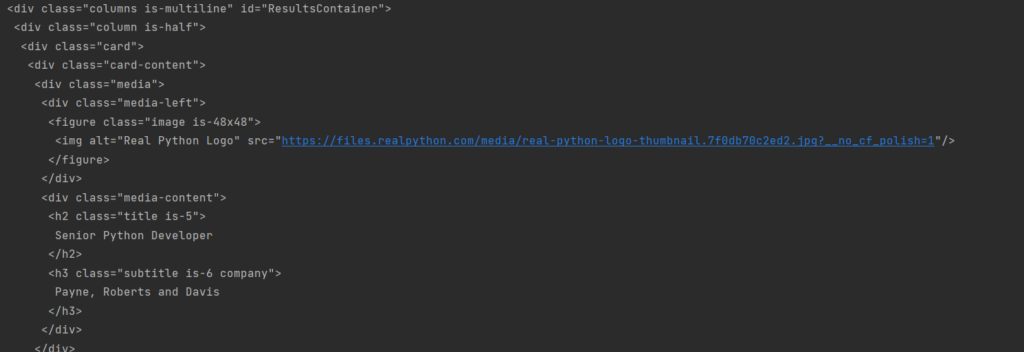
И да, мы получили уже конкретный блок необходимых данных, но это только начало.
Ищем элементы по имени класса
Смотрим дальше. Внутри каждой из полученных карточек есть объект с классом card-content. Мы можем это использовать, чтобы получить массив из всех элементов, которые содержат этот класс.
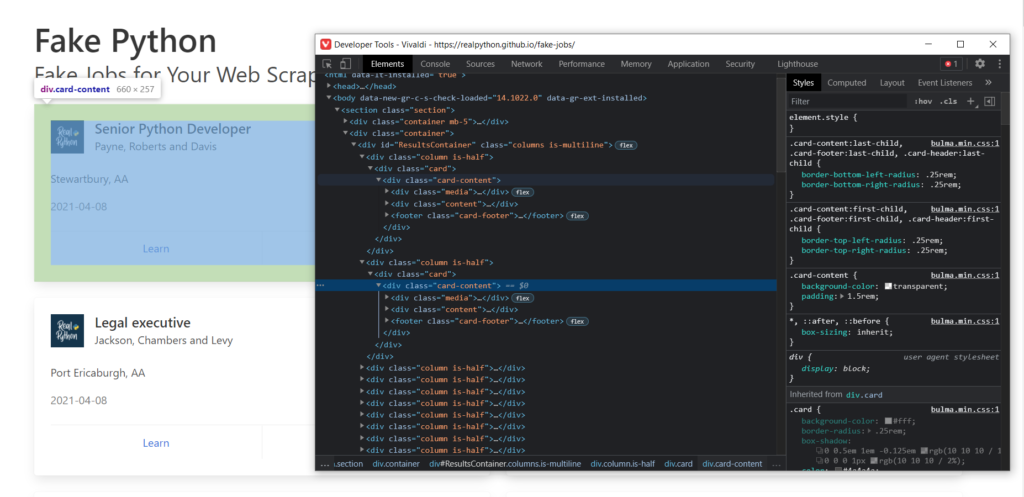
Но так как мы хотим получить только элементы из последнего блока данных, а не всего сайта, то теперь вызываем find_all не от soup, а от results. Достаточно простая система.
|
1 2 3 4 5 |
job_elements = results.find_all("div", class_="card-content") for job in job_elements: print("\n\n") print(job.prettify()) |
Я сразу вывел каждую карточку отдельно, но с отступами:
Теперь это не один блок кода, а множество однообразных маленьких. А мы ещё на шаг ближе к цели.
Посмотрим на первый элемент. Тут есть элемент h2 и элемент h3. Они отображают должность и компанию соответственно. При этом у них есть ещё и особые классы: title и company. А ещё есть параграф p с классом location.
Но p, h2 и h3 это не id и не class, так что немного изменим наши параметры для более точной работы функции find.
|
1 2 3 4 5 6 7 8 |
for job in job_elements: title_element = job.find("h2", class_="title") company_element = job.find("h3", class_="company") location_element = job.find("p", class_="location") print(title_element) print(company_element) print(location_element) print() |
Запустите. Теперь выбираем только тогда, когда конкретный компонент имеет указанный класс. Так получим подходящие данные из карточек. Правда, всяк с html кодом. Но чтобы его отбросить просто в print добавляем .text:
|
1 2 3 4 5 6 7 8 |
for job in job_elements: title_element = job.find("h2", class_="title") company_element = job.find("h3", class_="company") location_element = job.find("p", class_="location") print(title_element.text) print(company_element.text) print(location_element.text) print() |
Вывод:
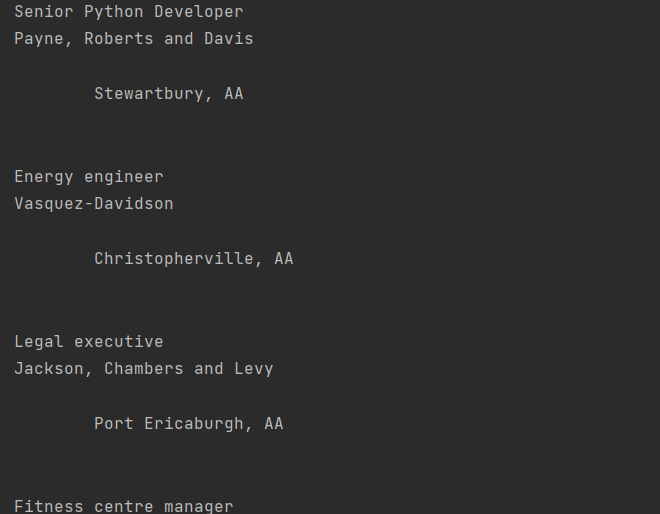
Почти, но местоположение куда-то отпрыгивает из-за наличия кучи лишних отступов. Но так как мы уже выводим не какие-то объекты BS4, а обычные питоновские строки, то мы можем использовать .strip() чтобы удалить все пробелы в начале и конце строки:
|
1 2 3 4 5 6 7 8 |
for job in job_elements: title_element = job.find("h2", class_="title") company_element = job.find("h3", class_="company") location_element = job.find("p", class_="location") print(title_element.text.strip()) print(company_element.text.strip()) print(location_element.text.strip()) print() |
Теперь мы получили большой список должностей, компаний и их местоположений, который в точности совпадает с сайтом, так как и взят именно оттуда. Для наглядности сравним:
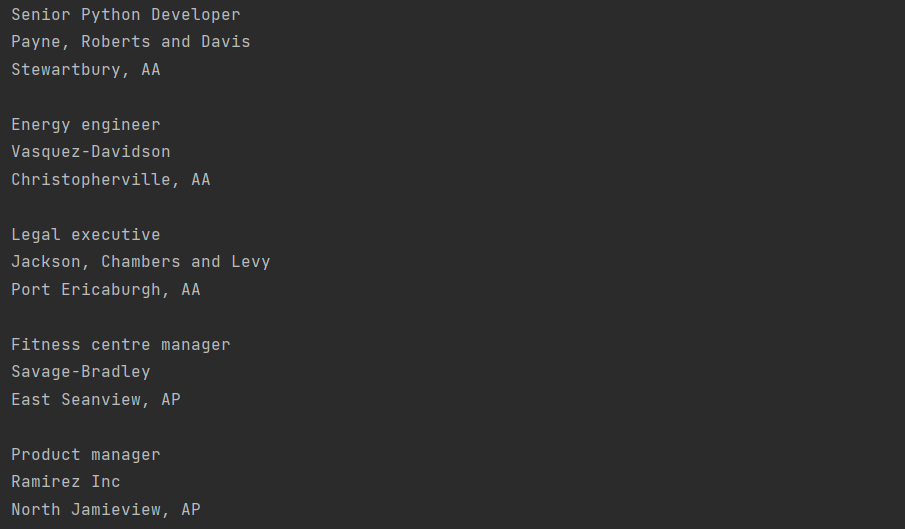
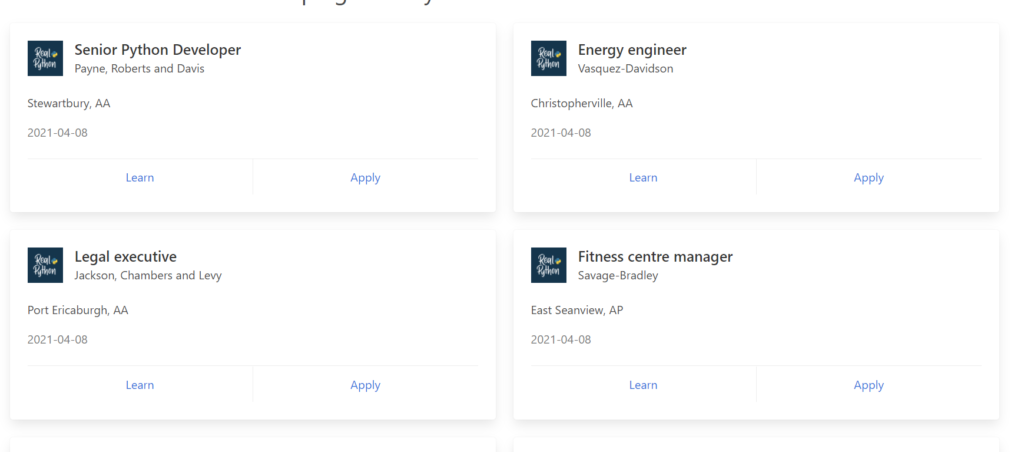
Ищем элементы по содержимому
Да, мы вывели буквально ВСЕ доступные профессии. Но BeautifulSoup позволяет не только найти по параметрам, но и отсеять по-содержимому. Предлагаю закомментировать список всех работ и дописать новый запрос:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# job_elements = results.find_all("div", class_="card-content") # # for job in job_elements: # title_element = job.find("h2", class_="title") # company_element = job.find("h3", class_="company") # location_element = job.find("p", class_="location") # print(title_element.text.strip()) # print(company_element.text.strip()) # print(location_element.text.strip()) # print() python_jobs = results.find_all("h2", string="Python") print(python_jobs) |
И запускаем.
Ничего? Не удивительно. Попробуйте найти там вакансию, которая состоит из одного только слова Python. Find_all ищет точное соответствие для такого запроса, но таких в списке нет. Как вы знаете, даже регистр будет влиять на результат, и это нужно учитывать.
Если мы хотим включить все карточки, где есть определённое слово (python, например), то нужно использовать лямбда функцию. Изменим код выше на этот:
|
1 2 3 4 5 6 |
python_jobs = results.find_all( "h2", string=lambda text: "python" in text.lower() ) for job_title in python_jobs: print(job_title.text.strip()) |
И теперь мы передали string= не конкретный текст, а функцию, при выполнении условий которой элемент будет добавлен. Запускаем снова. Теперь у нас отобразили целый список подходящих вакансий:
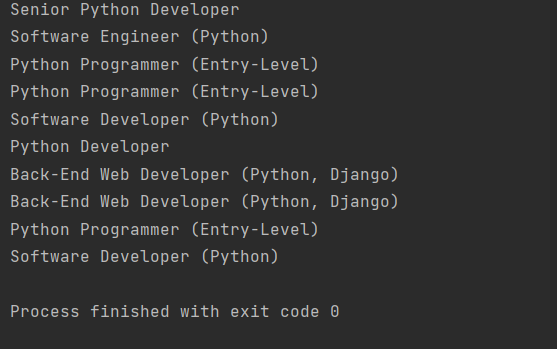
Обращаемся к родителям найденных результатов
Смотрите, только что мы выбрали только заголовки должностей, но компании и остальные данные оказались вне выборки. Но мы знаем, что заголовок h3 с названием компании был в том же блоке, что и заголовок h2 названием должности. Следовательно, если мы перейдём в родителя h2, то сможем выйти и на h3.
|
1 2 3 4 |
<div class="media-content"> <h2 class="title is-5">Senior Python Developer</h2> <h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3> </div> |
Давайте попробуем это сделать.
Меняем последний цикл, который выводил выбранные вакансии с питоном на такой блок:
|
1 2 3 4 5 6 |
for job_title in python_jobs: parent = job_title.parent company_element = parent.find("h3", class_="company") print(job_title.text.strip()) print(company_element.text.strip()) print() |
В первой же строке я при помощи .parent обращаюсь к родителю заголовка, а это div с классом с media-content, а уже в нём ищу h3 company. И нахожу:
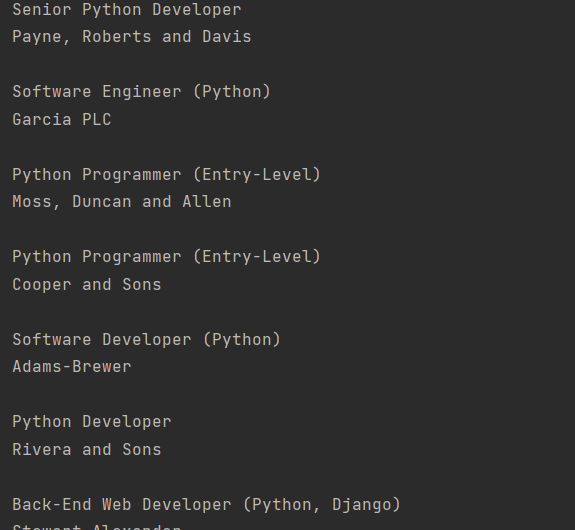
Всё тот же список с Python вакансиями, но теперь ещё и с компаниями. Иногда так даже удобнее.
Извлекаем аттрибуты объектов в BeautifulSoup
Мы научились получать текстовое содержимое объектов. Но у каждой карточки есть две кнопки. Попробуем получить их и вывести содержимое. Я поступлю очень лениво и просто из предыдущего примера вернусь к родителю родителя родителя и найду в нём footer карточки, в котором и лежат обе кнопки-ссылки:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
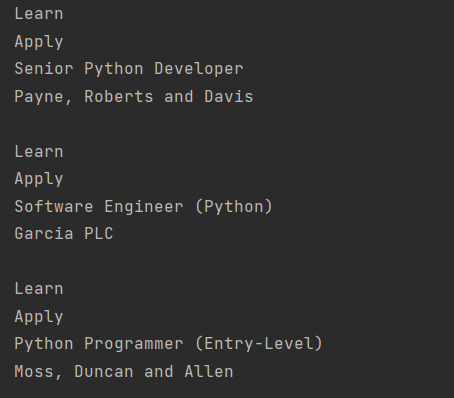
for job_title in python_jobs: parent = job_title.parent company_element = parent.find("h3", class_="company") card_parent = parent.parent.parent.parent card_footer = card_parent.find("footer", class_="card-footer") card_links = card_footer.find_all("a") for link in card_links: print(link.text.strip()) print(job_title.text.strip()) print(company_element.text.strip()) print() |
Вот только понимаете, в чём беда, текст ссылки есть, а ссылки – нет. Сомнительная польза.
Это связанно с тем, что ссылка href является частью html, это атрибут. И если мы хотим получить текст элемента, то весь html (в т.ч. и атрибуты) будет отброшен. Что мы и увидели. Но извлечь атрибуты из объекта довольно просто. В этом нам помогут квадратные скобки и имя атрибута.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
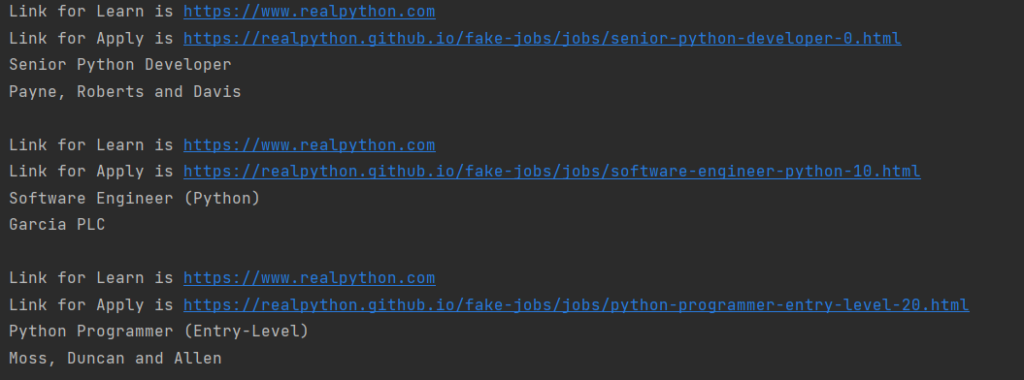
for job_title in python_jobs: parent = job_title.parent company_element = parent.find("h3", class_="company") card_parent = parent.parent.parent.parent card_footer = card_parent.find("footer", class_="card-footer") card_links = card_footer.find_all("a") for link in card_links: link_url = link["href"] link_text = link.text.strip() print(f"Link for {link_text} is {link_url}") print(job_title.text.strip()) print(company_element.text.strip()) print() |
Результат лучше, чем можно было бы мечтать:
Теперь эти данные готовы для любой обработки, хоть в БД кидай, хоть на сервер пересылай. При этом никто не запрещает вам перейти по новым ссылкам и собрать какие-то данные оттуда. Таким образом можно было бы собрать полные данные о вакансии в одно месте, без необходимости перехода.
На этом пока всё, спасибо за внимание!
Ещё по Python: Графика в Python при помощи модуля Turtle. Часть 1



