
Привет! Основной мой профиль это Android и Unity. Kotlin и C# отличные ребята, но для автоматизации рутины идеалом оказался таки… Python. Не видел нигде столько библиотек для решения всего. Буквально. BeautifulSoup, PyGame, Flask, AIOGram (хотя это уже фреймворк для телеги, но не суть).
Вот задумал сделать простенькое приложение с чек листами жизни, раз они имеют спрос +-. И решил выкачать пару готовых. Два чек листа я знаю уже давно: первый и второй. Но не копировать же их руками! И тогда я вспомнил о BeautifulSoup и запустил PyCharm. А тут поделюсь ещё одним примером автоматизации сбора данных с веб-страничек.
Установка BS и остальное
Уже было в этой статье, повторяться не хочется: Учимся парсить веб-сайты на Python + BeautifulSoup
Приступаем
Начинаем с импорта необходимого и ссылки жертвы:
|
1 2 3 4 |
import requests from bs4 import BeautifulSoup url = "https://shevchenko.cc/in/lifechecklist/" |
Далее загружаем страничку и закидываем в суп:
|
1 2 3 |
page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') |
Как видим в инспекторе браузера (Ctrl + Shift + I), все данные удачно сложены в div с классом “check”:

Значит находим конкретно этот блок и отбросим лишнее:
|
1 |
content = soup.find(class_="check") |
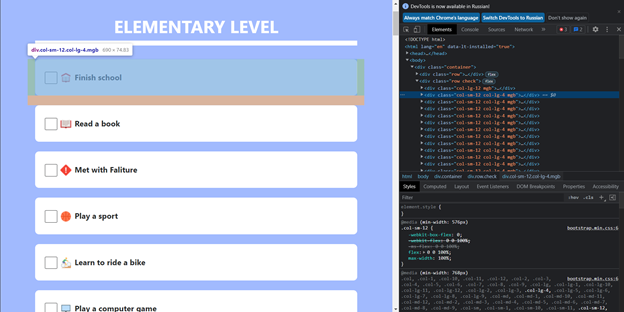
На скрине видно, что каждый отдельный элемент содержит класс col-sm-12, а значит можно выбрать все дочерние элементы, которые содержат этот класс. В результате получаем все пункты, но в сыром виде.
|
1 |
check_items = content.findAll(class_="col-sm-12") |
Для своего приложения я решил использовать эмодзи, поэтому изображения меня не особо интересовали, а в самой карточке очень удачно оказался отдельный div с текстом. Он то нам и нужен!

Значит создаём цикл, где перебираем все карточки и вытаскиваем из них текст. Т.к. я это делал для приложения Android, то я сразу обернул это всё в подходящий формат строковых ресурсов:
|
1 2 3 4 |
for item in check_items: text = item.find(class_="checkText").text name = str(text).replace(" ", "_").lower() print(f"<string name=\"{name}\">{text}</string>") |
И результат вот:
|
1 2 3 4 5 6 7 |
<string name="finish_school">Finish school</string> <string name="read_a_book">Read a book</string> <string name="met_with_faliture">Met with Faliture</string> <string name="play_a_sport">Play a sport</string> <string name="learn_to_ride_a_bike">Learn to ride a bike</string> <string name="play_a_computer_game">Play a computer game</string> <string name="make_a_friend">Make a friend</string> |
Буквально 5 минут и я получил готовые ресурсы для приложения. Ну не прекрасно ли?
Весь код вот:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import requests from bs4 import BeautifulSoup url = "https://shevchenko.cc/in/lifechecklist/" page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') content = soup.find(class_="check") check_items = content.findAll(class_="col-sm-12") for item in check_items: text = item.find(class_="checkText").text name = str(text).replace(" ", "_").lower() print(f"<string name=\"{name}\">{text}</string>") |
Второй сайт
Как я и сказал, списка было два. Отличий будет не так много, а вернее всего одно, уже при финальной обработке карт.
Снова импорты, загружаем сайт:
|
1 2 3 4 5 6 7 8 |
import requests from bs4 import BeautifulSoup url = "https://neal.fun/life-checklist/" page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') |
Так же выбираем контейнер с карточками, в этот раз он называется “goals”. Тут же видим, что каждая карточка наследует класс “goal-wrapper”:
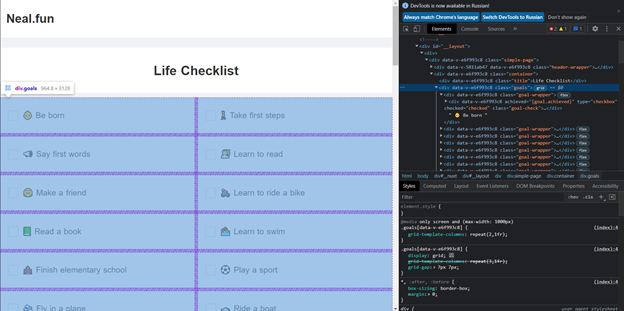
|
1 2 3 |
content = soup.find(class_="goals") check_items = content.findAll(class_="goal-wrapper") |
И наконец нас ждёт это самое отличие. Если в первом случае текст был удобно вынесен в отдельный блок, то тут текст является частью контента всей карточки:

Да ещё и иконки сразу в строке.
Но это не беда. Ведь теперь мы просто получаем напрямую text из самой карточки, а средствами питона отрезаем первое «слово» от строки. Я говорил, что использую эмодзи, но в строке они мне не нужны.
|
1 2 3 4 5 6 |
for item in check_items: text = str(item.text).replace("\n", "") text = text.split(' ', 1)[1] name = text.lower().replace(" ", "_") print(f"<string name=\"{name}\">{text}</string>") |
Всё, аналогичный первому результат получен, вы прекрасны!
|
1 2 3 4 5 6 7 |
<string name="be_born">Be born</string> <string name="take_first_steps">Take first steps</string> <string name="say_first_words">Say first words</string> <string name="learn_to_read">Learn to read</string> <string name="make_a_friend">Make a friend</string> <string name="learn_to_ride_a_bike">Learn to ride a bike</string> <string name="read_a_book">Read a book</string> |
Полный код второй части:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import requests from bs4 import BeautifulSoup url = "https://neal.fun/life-checklist/" page = requests.get(url) soup = BeautifulSoup(page.content, 'html.parser') content = soup.find(class_="goals") check_items = content.findAll(class_="goal-wrapper") for item in check_items: text = str(item.text).replace("\n", "") text = text.split(' ', 1)[1] name = text.lower().replace(" ", "_") print(f"<string name=\"{name}\">{text}</string>") |



